 KITTEN: A Knowledge-Integrated Evaluation of
KITTEN: A Knowledge-Integrated Evaluation of
Image Generation on Visual Entities
*: Equal Contribution
1 ![]()
2 ![]()
KITTEN: A Knowledge-Integrated Evaluation of
1 ![]()
2 ![]()
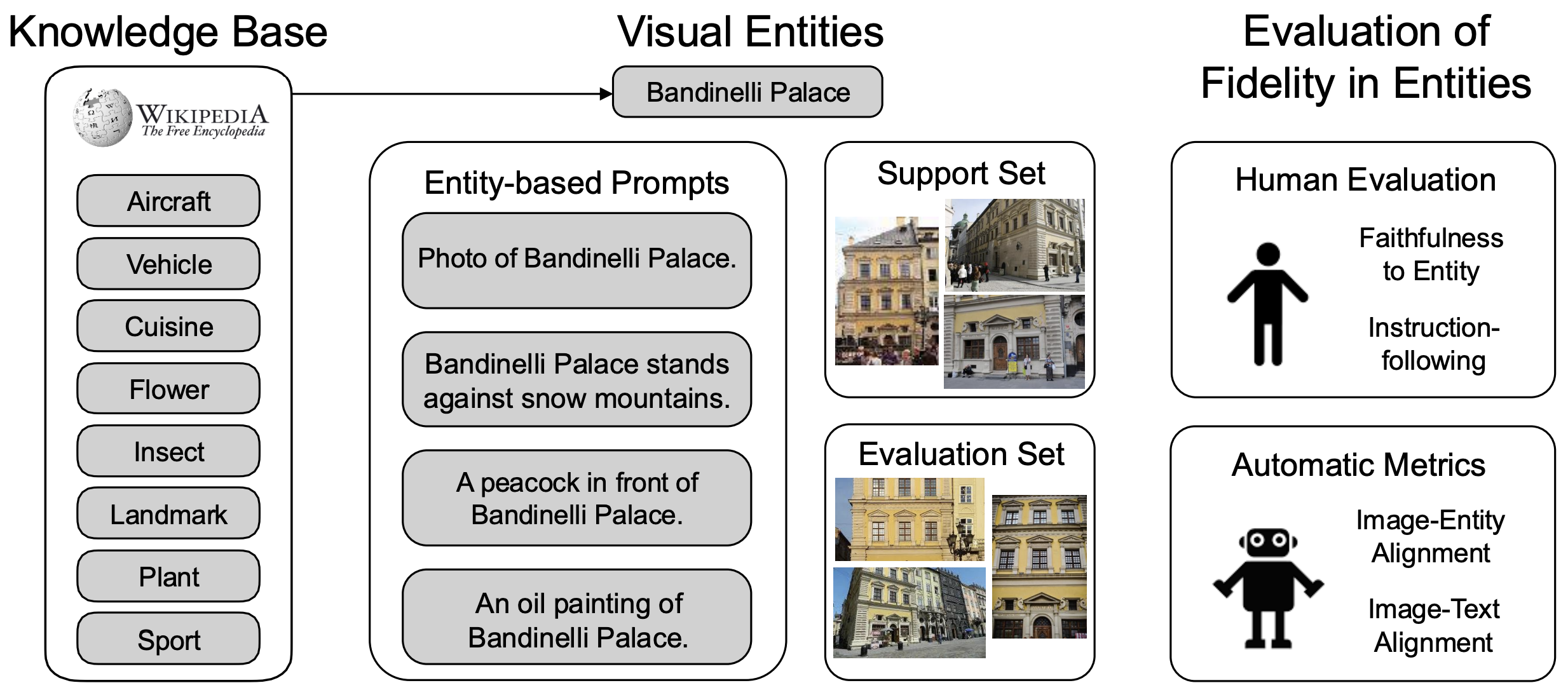
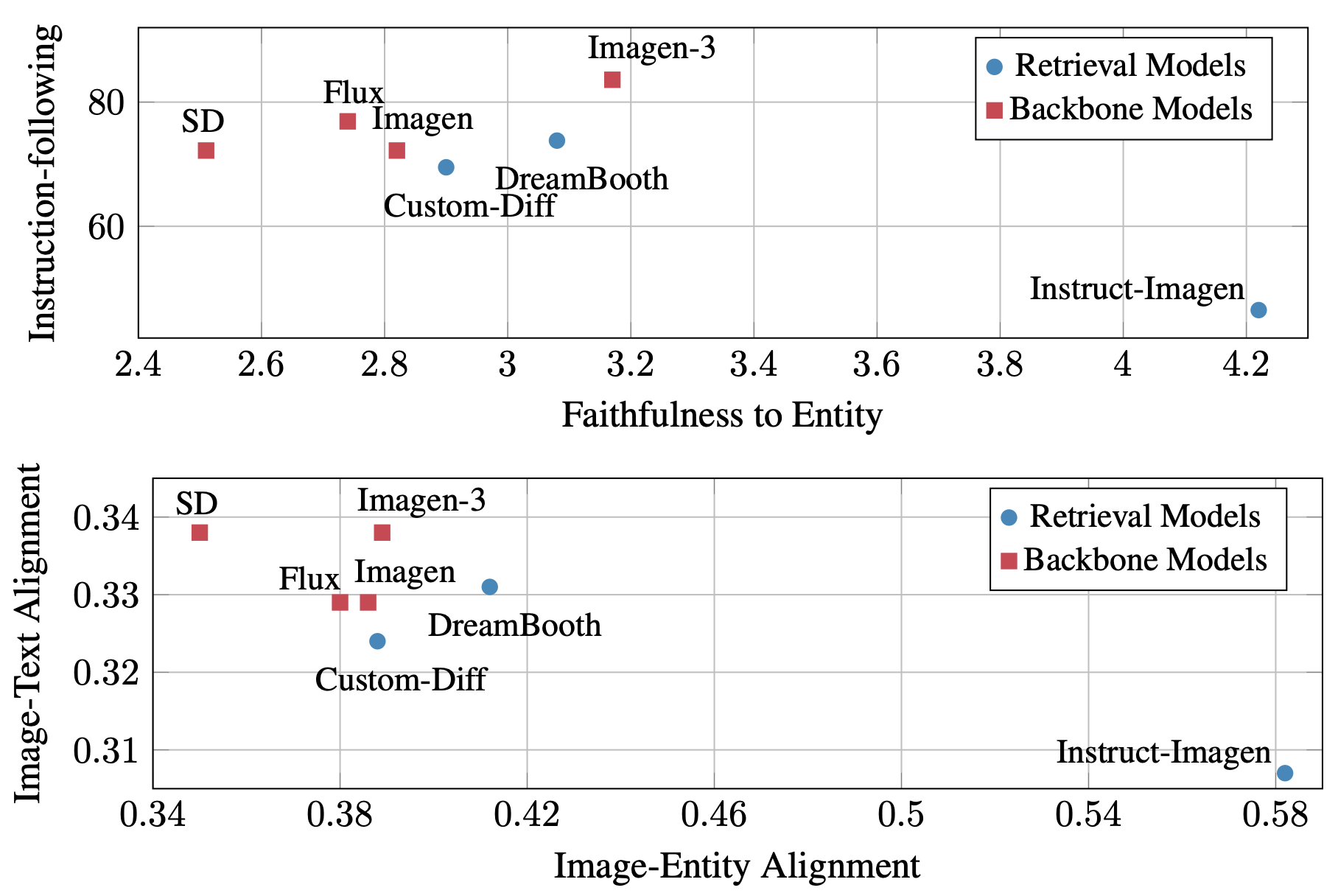
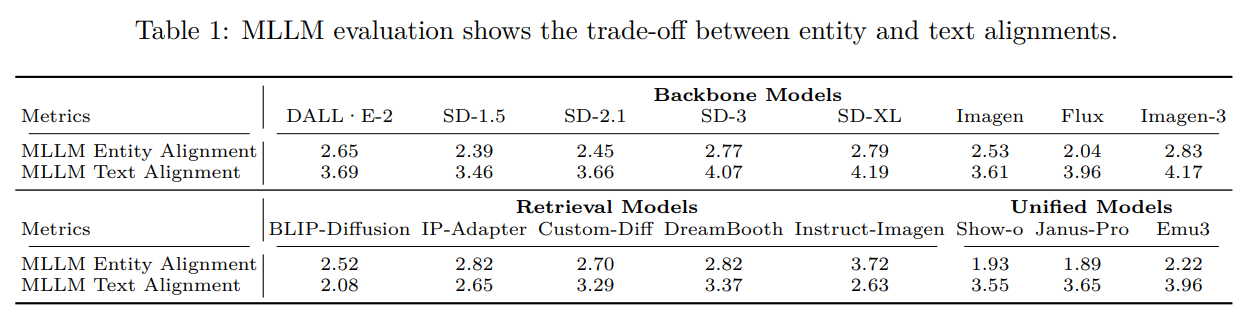
Recent advances in text-to-image generation have improved the quality of synthesized images, but evaluations mainly focus on aesthetics or alignment with text prompts. Thus, it remains unclear whether these models can accurately represent a wide variety of realistic visual entities. To bridge this gap, we propose Kitten, a benchmark for Knowledge-InTegrated image generaTion on real-world ENtities. Using Kitten, we conduct a systematic study of recent text-to-image models, retrieval-augmented models, and unified understanding and generation models, focusing on their ability to generate real-world visual entities such as landmarks and animals. Analyses using carefully designed human evaluations, automatic metrics, and MLLMs as judges show that even advanced text-to-image and unified models fail to generate accurate visual details of entities. While retrieval-augmented models improve entity fidelity by incorporating reference images, they tend to over-rely on them and struggle to create novel configurations of the entities in creative text prompts.




@article{huang_2026_kitten,
title = {{KITTEN}: A Knowledge-Integrated Evaluation of Image Generation on Visual Entities},
author={Huang, Hsin-Ping and Wang, Xinyi and Bitton, Yonatan and Taitelbaum, Hagai and
Tomar, Gaurav Singh and Chang, Ming-Wei and Jia, Xuhui and Chan, Kelvin C.K. and
Hu, Hexiang and Su, Yu-Chuan and Yang, Ming-Hsuan},
journal={Transactions on Machine Learning Research},
year={2026}
}